






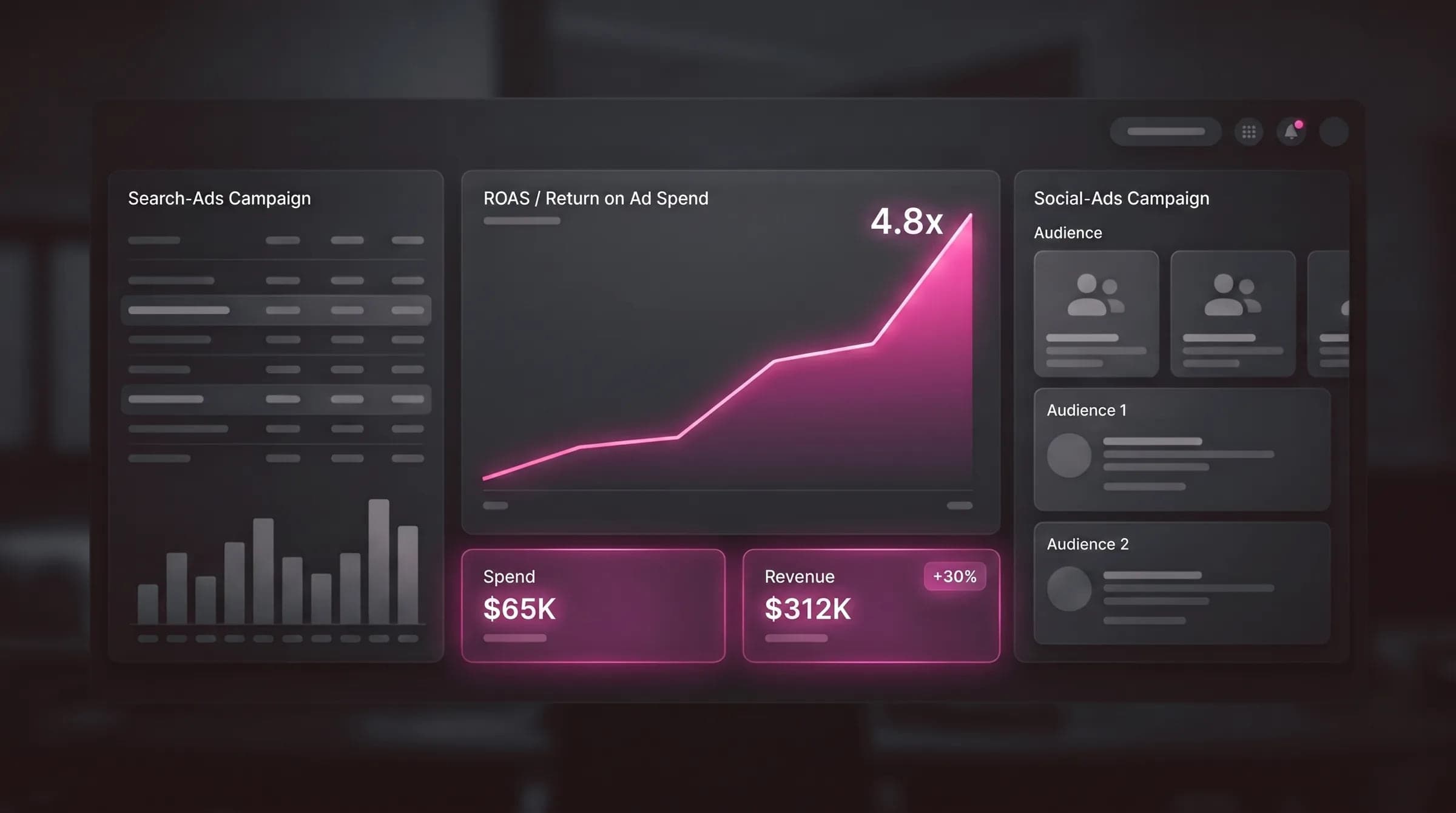








AI agents fail in production because the demo and the real world are different problems. A demo only has to work once, on a clean input, with a logged-in user watching. Production has to work every time — through expired tokens, broken handoffs between steps, edge-case inputs, and actions no human is there to catch. The model is rarely the issue; the engineering around it is.
That gap is why so many agents look magical in a sales deck and stall the week after launch. Below is what actually breaks, in the order it usually breaks.
Why AI agents fail in production: the short answer
Most production failures trace back to four root causes — not to a weak LLM:
- Brittle handoffs. Multi-step agents chain tool calls; one bad step silently corrupts every step after it.
- Broken auth. Agents need live access to APIs and internal systems; tokens expire and scopes drift.
- No human-in-the-loop. Nothing catches a wrong, irreversible action before it executes.
- Immature web infrastructure. The web wasn't built for autonomous agents clicking, scraping, and calling at machine speed.
Fix those four and most "the agent is unreliable" complaints disappear.
The four failure modes, in detail
1. Brittle multi-step handoffs
An agent that books travel might call six tools in sequence: search, select, price-check, reserve, pay, confirm. In a demo, all six fire cleanly. In production, step three returns a malformed price, the agent doesn't notice, and steps four through six build on bad data. Without checkpoints, validation between steps, and the ability to stop and ask, one weak link fails the whole chain — quietly.
2. Authentication and permissions
This is the most common reason an agent that "worked yesterday" breaks today. Agents act on live systems, so they live and die by tokens, scopes, and rate limits. A token refreshes and the new one has narrower scope. A SaaS API tightens its limits. An internal service was never granted to the agent's service account. None of these show up in a happy-path demo — and all of them are the first thing to break under real traffic.
3. No human-in-the-loop ("babysitting")
Teams either over-trust the agent (let it send the email, refund the customer, push the deploy — and clean up the mess) or under-trust it (a human approves every step, so the "automation" saves nothing). The reliable middle is risk-tiered approval: let the agent act freely on reversible, low-stakes steps, and require a human checkpoint only on irreversible or high-cost ones.
4. Immature agent web infrastructure
The web assumes a human with a browser and a session. Agents hit sites that block automation, layouts that shift, auth flows built for people, and APIs with no agent-friendly contract. Much of today's web simply isn't ready for autonomous agents — so production agents need fallbacks, retries, and graceful degradation when the environment doesn't cooperate.
Demo vs production: what actually changes
The same agent faces a completely different bar once it leaves the demo:
Demo / POC
- Inputs are clean and expected
- One logged-in session
- Failure handling is "try again"
- Someone is watching the run
- Tool calls stay on the happy path
- A mistake costs nothing
- Observability is console logs
Production
- Inputs are messy, adversarial, edge-case
- Expiring tokens, shifting scopes, rate limits
- Retries, rollback, and alerting required
- Runs unattended at scale
- Malformed responses, timeouts, partial failures
- A mistake means a wrong refund, bad deploy, lost data
- Traces, evals, and an audit trail
How to ship an agent that survives production
Reliable agents are engineered like distributed systems, not like chatbots. A production-ready build checks these boxes:
| Requirement | Why it matters |
|---|---|
| Narrow, well-defined scope | Fewer steps and tools mean fewer ways to fail |
| Schema-validated tool I/O | Catches hallucinated arguments and malformed responses |
| Checkpoints between steps | Stops a bad handoff from poisoning the chain |
| Risk-tiered human approval | A human catches irreversible actions; the rest run free |
| Robust auth handling | Token refresh, scope checks, and rate-limit backoff |
| Observability + evals | You can see why a run failed and measure regressions |
| Fallbacks and rollback | The agent degrades gracefully instead of breaking |
This is exactly the work that separates a $25K proof-of-concept from an enterprise agent that can run >$500K — the production engineering, not the prompt.
This is also why we treat agent reliability as an engineering discipline in our AI agent development practice: scope tightly, validate every tool call, tier the approvals, and instrument the whole run before it ever touches real traffic.
The scale of the gap is well documented: industry analysts now estimate that the majority of agentic AI pilots — by some 2026 forecasts, more than 40% — never make it to production, almost always for the engineering reasons above rather than a weak model. That's the same reason the wedge matters. The big-name agent shops — IBM, OpenAI's enterprise arm, LeewayHertz and the offshore studios in India and Dubai — can all build the demo. What separates an agent that survives is the unglamorous hardening, and that work goes faster when the team doing it shares your business hours. WeEvolveIT runs that hardening nearshore from Monterrey: a senior engineer is online when your token expires at 2pm your time, not 12 hours later, so the broken handoff gets caught and fixed the same afternoon instead of the next sprint.
Does this mean AI agents don't work?
No. AI agents work — when the task is scoped, the tools are well-defined, and the failure modes above are engineered out from the start. They fail when teams ship a demo into production and expect the happy path to hold. The agents that survive aren't built on better models; they're built with checkpoints, validated tools, human approval where it counts, and real observability.
The bottom line
Why AI agents fail in production is rarely about intelligence — it's about handoffs, auth, oversight, and infrastructure. Treat your agent like a system that will face messy inputs, expiring tokens, and unattended runs, and design for those from day one. Do that, and the agent that wowed in the demo becomes the one that quietly keeps working in production.